

多元判定係數與標準化迴歸係數的詮釋
Multiple Linear Regression, MLR Interpretation
神掌打通任督二脈‧易筋經以簡馭繁
符號意義: 統雄快訣
統雄快訣
 延伸閱讀
延伸閱讀
 進階議題
進階議題
 警示訊息
警示訊息
|
多元迴歸目的是以多個獨立自變項預測一個應變項,本文解說:迴歸係數與相關係數之不同,多元迴歸之變異數分析,假設檢定,多元判定係數,多元相關係數,未標準化迴歸係數,標準化迴歸係數,與自變項篩選方法。辨別b與β 的關係:變動vs.預測力。 下載SPSS範例實作,解說什麼是:迴歸方法的選擇、選擇變數(Selection Variable)、觀察值標記(Case Labels)、加權變項(WLS Weight)、選擇統計量、與報表詮釋。 |
多元迴歸分析特色
多元迴歸的目的是以多個自變項預測一個應變項,分析各自變項對應變項「獨立影響」的程度;同時具備篩選自變項的能力,從而發展、檢定多個包含不同自變項的模式。
多元迴歸分析是由Pearson(1908)所提出, 在傳統古典統計學教科書上,都把這項觀念作為統計的最高技術,實務上,也是建構各種多變項模型的基礎、扮演最重要的技術角色。
In statistics, linear regression is an approach to modeling the relationship between a scalar dependent variable y and one or more explanatory variables denoted X. The case of one explanatory variable is called simple regression. More than one explanatory variable is multiple regression. (This in turn should be distinguished from multivariate linear regression, where multiple correlated dependent variables are predicted, rather than a single scalar variable.)
In linear regression, data is modeled using linear predictor functions, and unknown model parameters are estimated from the data. Such models are called linear models. Most commonly, linear regression refers to a model in which the conditional mean of y given the value of X is an affine function of X. Less commonly, linear regression could refer to a model in which the median, or some other quantile of the conditional distribution of y given X is expressed as a linear function of X.
理論概念模型 |
分析方法與其說明 |
多因子相關理論多元迴歸模型因子間關係:彼此獨立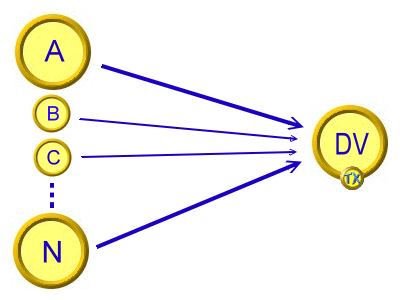
|
目的各因子共同作用時,是否對應變項產生獨立影響,與其影響的程度。 差異/相關理論的概念模型完全相同,區別理論類型與統計工具的選擇方法如下。 SPSS 工具應變項:連續資料/自變項:連續資料多元迴歸分析。 多個連續資料之自變項,個別對應變項預測力的分析。 因子獨立性這項模型成立的前提是各因子之間具備獨立性。 但因子之間可能因具備「交互作用」或「共線性」或「中介作用」而不符獨立性,就必須作進一步分析,發展不同的模型。 |
多元迴歸統計模式
In MLR, the goal is to predict, knowing the measurements collected on N
subjects, the value of the dependent variable Y from a set of K independent
variables {X1, . . . ,Xi, . . . ,Xk}. We denote by X
the N × (K + 1) augmented matrix collecting the data for the independent
variables (this matrix is called augmented because the first column is
composed only of ones), and by y the N × 1 vector of observations for the
dependent variable.
Multiple regression finds a set of partial regression coefficients bk
such that the dependent variable could be approximated as well as possible
by a linear combination of the independent variables (with the bi
』s being the weights of the combination). Therefore, a predicted value,
denoted Y , of the dependent variable is obtained as the following:
Y = b0 + b1X1 + b2X2 + ... + bkXk + e
對「第1類知識」而言,是肯定迴歸現象存在,而沒有真實誤差項 e的多元一次方程式,如果觀察值並不完全符合迴歸方程式,是工具誤差、傳導誤差所造成的。
對「第2類知識」的統計「逆向」思想而言,就必須考慮「看到的迴歸不是真的迴歸」,就母群而言包括真實誤差項e,這個誤差是理論不正確所造成的。
多元迴歸統計模式中的 b 若作 β,e 作 ε,表達不同的意義。有些文獻混淆不清,讀者必須特別注意提防。這些符號的正確意義與運用,以下再詳細說明。
每1個Xi 必須是彼此獨立的,幾何學上的意義就是必須是彼此兩兩正交(pairwise orthogonal)的。
淨迴歸係數 Partial Regression Coefficients
以上的 bi,是不考慮誤差項 e時,由偏微分的最小平方法(Least squares)計算而得,故可特稱為淨迴歸係數 Partial Regression Coefficients。表示每1個Xi ,單獨對Y 的影響方向與程度,屬微積分與幾何學上的意義。
推算 bi所採用的最小平方法,還包括各種子途徑,如OLS, PLS…等,屬於演算的進階論題,在此不深敘。
The partial regression coefficient is also called regression coefficient,
regression weight, partial regression weight, slope coefficient or partial
slope coefficient. It is used in the context of multiple linear regression
(MLR) analysis and gives the amount by which the dependent variable (DV)
increases when one independent variable (IV) is increased by one unit and
all the other independent variables are held constant. This coefficient is
called partial because its
value depends, in general, upon the other independent variables.
Specifically, the value of the partial coefficient for one independent
variable will vary, in general, depending upon the other independent
variables included in the regression equation.
未標準化迴歸係數 Unstandardized Coefficients
根據以上程序產生的多元迴歸係數,具備彼此獨立性,也是迴歸方程式的係數值,表現的是幾何上的斜率概念。在統計思想中,特稱為未標準化迴歸係數。
多元迴歸之變異數分析
對統計思想而言,就必須考慮誤差項 e的作用,而進行變異數分析,以便進一步作迴歸係數 bi,是否顯著的假設檢定。
SSR: SS of Regression
SSE: SS of Error
SST: SS of Total
其中「迴歸」即為可預測部分,「隨機」即誤差部分,又是不同名詞,相同意義。

多元判定係數 Multiple Determination Coefficient
統計思想會考慮模式解釋力、預測力的問題,所以有以下衡量指標。
R2 稱為多元判定係數(multiple determination coefficient),相當於總變異中可被解釋之百分比。
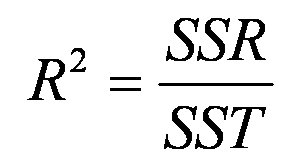
調整判定係數 Adjusted R2
如果自變項的個數很多,就要用調整後的判定係數代替原始的判定係數,因為自變項愈多,R2 會變大,調整以避免膨脹。
多元相關係數 Multiple Correlation Coefficient
0 =< R =< 1
R < .3 |
相關性不重要 |
.3 < R <.7 |
相關重要性中低,視個案而定。 |
.7< R <.9 |
相關性具重要性 |
.9 <R |
相關性具高重要性 |
標準化迴歸係數 Standardized Coefficients
未標準化迴歸係數的單位,因各自變項不同而不同,所以無法彼此比較。
而作多元迴歸的目的,通常是要比較各自變項之間的預測力,這時就要使用標準化迴歸係數。
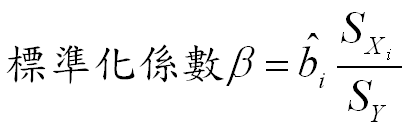
亦即:各未標準化迴歸係數,乘上:「自變項之標準差除以應變項之標準差」。
前置標準化
有些研究分析程序,是在「資料整理」階段,就將資料集「標準化」,亦即將資料全部轉換為平均數為0,測量值為-1至1的資料。
這是在電腦發明以前的可簡化計算的方式,以今日的電腦能力,已無如此處理必要。
以標準化資料所計算的淨迴歸係數,就是標準化迴歸係數。
b與β 的關係:變動vs.預測力
![]() 注意:有些文獻,b與β不分。不僅弄昏讀者,更使未標準化與標準化迴歸係數混淆,造成嚴重觀念錯誤。
注意:有些文獻,b與β不分。不僅弄昏讀者,更使未標準化與標準化迴歸係數混淆,造成嚴重觀念錯誤。
有些文獻用 b 表示樣本迴歸係數,β表示母群迴歸係數;以類比以![]() 表示樣本平均數,以
μ 表示母群平均數,在溝通上也容易產生困擾。
表示樣本平均數,以
μ 表示母群平均數,在溝通上也容易產生困擾。
![]() 在觀念正確、與名詞一致的考量上,應用 b 表示未標準化迴歸係數,β 表示標準化迴歸係數,SPSS報表也是遵循此準則。
在觀念正確、與名詞一致的考量上,應用 b 表示未標準化迴歸係數,β 表示標準化迴歸係數,SPSS報表也是遵循此準則。
b 表示的是幾何學上斜率、變動程度的意義,而 β 表示的是對樣本、對已發生事件解釋力、或對母群、對未來預期事件的預測力。
假設檢定
多元迴歸之假設檢定,就是檢定各自變項對對應變項「獨立影響」的程度 β。
假設檢定的呈現法,包括總檢定與邊際檢定兩種。
總檢定
假設迴歸模式中的所有 β 係數是否全部為0。
當 β 係數不全為0時,Y與(X1,X2,…,XK)才具有對應變項的的函數關係與預測力。
H0: β1=
β2=
... = βk=
0
H1: βj≠0,對某些j (j=1,2,…,K)
個別檢定 Marginal Tests(一般常用)
假設個別自變項之 β 係數(j, j=1,2,…,K)是否為0,共要作K次檢定。
H0: βj=0 (j=1,2,…,K)
H1: βj≠0
|
個別檢定/自變項篩選方法
個別檢定等同篩選掉迴歸方程式中,β﹦0的自變項。
自變項篩選方法有4種,根據每一自變項預測力之大小決定刪去或留在模式中。
驗證式/主觀式迴歸法(All-Possible-Regression Procedure /Enter)
注意:一般譯為:強迫進入法/ 輸入法,非常不能達意!
這是最古老的方法,不由系統作最佳化篩選,所有自變項按照使用者所訂順序,計算報告其β值,等於沒有篩選。
唯從現代眼光,原始的主觀,卻剛好可以作為「驗證式研究」分析使用。亦即驗證過去研究發現,各自變項的重要程度是否具備可複製性。
![]() 注意:為彰顯其應用特色,統雄老師特命名為「驗證式迴歸法」,這種方法,『會』有「共線性」與「允差」的問題。
注意:為彰顯其應用特色,統雄老師特命名為「驗證式迴歸法」,這種方法,『會』有「共線性」與「允差」的問題。
後退淘汰法(Backward Elimination Procedure)
先將所有的自變項放入迴歸方程式中,然後根據淘汰標準一一將不符合標準的自變項加以淘汰。適用特殊研究。
前進選擇法(Forward Selection Procedure)
第一個進入迴歸方程式的自變項是與應變項有最大相關的自變項,第一個自變項進入模型之後,再以對判定係數值大小的影響,檢查第二個自變項該誰進入,依此類推,直到沒有其他的自變項符合選取的標準為止。適用特殊研究。
探索式/逐步迴歸法(Stepwise Regression Procedure)
結合前進選擇法與反向淘汰法二種程序。首先採用順向選擇法,選進與應變項有最大相關的自變項,接下來以反向淘汰法檢查此自變項是否須加以排除。為了避免相同的自變項重複地被選進或排除,選進的標準(α值)必須小於淘汰的標準。
亦即,這種方法均經過最佳化篩選,所篩選之自變項均彼此獨立而互斥,不會有相依性。
在一般情況下,逐步迴歸法是「探索式研究」、或最後建構理論時,宜使用的方法。
![]() 注意:為彰顯其應用特色,統雄老師特命名為「探索式迴歸法」,這種方法,『不會』有「共線性」與「允差」的問題。
注意:為彰顯其應用特色,統雄老師特命名為「探索式迴歸法」,這種方法,『不會』有「共線性」與「允差」的問題。
曾經在論文研討場合,對逐步迴歸法所產生的成果,評論人猛問「相依性」,而作者目瞪口呆;可見,評論人與作者都不知道什麼是逐步迴歸法、相依性、「共線性」與「允差」。
多元迴歸的前提、限制、爭論與未來
在傳統古典統計學教科書上,都把多元迴歸分析作為統計的最高技術,實務上,也是建構各種多變項模型的基礎、扮演最重要的技術角色。
但多元迴歸之所以能夠分析,實有許多前提、限制、與爭論,如以下引文。然而這些即使以最科普的英文陳述,除非對統計非常有興趣的人,大概也很難懂。
統雄老師以教學的立場,白話詮釋如下:
The following are the major assumptions made by standard linear regression models with standard estimation techniques (e.g. ordinary least squares):
Weak exogeneity
自變項可具體測量,且為連續資料、或人為連續資料。
This essentially means that the predictor variables x can be treated as fixed
values, rather than random variables. This means, for example, that the
predictor variables are assumed to be error-free, that is they are not
contaminated with measurement errors. Although not realistic in many settings,
dropping this assumption leads to significantly more difficult
errors-in-variables models.
Linearity. This means that the mean of the response variable is a linear
combination of the parameters (regression coefficients) and the predictor
variables. Note that this assumption is much less restrictive than it may at
first seem. Because the predictor variables are treated as fixed values (see
above), linearity is really only a restriction on the parameters. The predictor
variables themselves can be arbitrarily transformed, and in fact multiple copies
of the same underlying predictor variable can be added, each one transformed
differently. This trick is used, for example, in polynomial regression, which
uses linear regression to fit the response variable as an arbitrary polynomial
function (up to a given rank) of a predictor variable. This makes linear
regression an extremely powerful inference method. In fact, models such as
polynomial regression are often "too powerful", in that they tend to overfit the
data. As a result, some kind of regularization must typically be used to prevent
unreasonable solutions coming out of the estimation process. Common examples are
ridge regression and lasso regression. Bayesian linear regression can also be
used, which by its nature is more or less immune to the problem of overfitting.
(In fact, ridge regression and lasso regression can both be viewed as special
cases of Bayesian linear regression, with particular types of prior
distributions placed on the regression coefficients.)
Constant variance (aka homoscedasticity)
變項同質性,亦即變項應符常態分配,且具相同變異性。
This means that different response variables have the same variance in their errors, regardless of the values of the predictor variables. In practice this assumption is invalid (i.e. the errors are heteroscedastic) if the response variables can vary over a wide scale. In order to determine for heterogeneous error variance, or when a pattern of residuals violates model assumptions of homoscedasticity (error is equally variable around the 'best-fitting line' for all points of x), it is prudent to look for a "fanning effect" between residual error and predicted values. This is to say there will be a systematic change in the absolute or squared residuals when plotted against the predicting outcome. Error will not be evenly distributed across the regression line. Heteroscedasticity will result in the averaging over of distinguishable variances around the points to get a single variance that is inaccurately representing all the variances of the line. In effect, residuals appear clustered and spread apart on their predicted plots for larger and smaller values for points along the linear regression line, and the mean squared error for the model will be wrong. Typically, for example, a response variable whose mean is large will have a greater variance than one whose mean is small. For example, a given person whose income is predicted to be $100,000 may easily have an actual income of $80,000 or $120,000 (a standard deviation of around $20,000), while another person with a predicted income of $10,000 is unlikely to have the same $20,000 standard deviation, which would imply their actual income would vary anywhere between -$10,000 and $30,000. (In fact, as this shows, in many cases – often the same cases where the assumption of normally distributed errors fails – the variance or standard deviation should be predicted to be proportional to the mean, rather than constant.) Simple linear regression estimation methods give less precise parameter estimates and misleading inferential quantities such as standard errors when substantial heteroscedasticity is present. However, various estimation techniques (e.g. weighted least squares and heteroscedasticity-consistent standard errors) can handle heteroscedasticity in a quite general way. Bayesian linear regression techniques can also be used when the variance is assumed to be a function of the mean. It is also possible in some cases to fix the problem by applying a transformation to the response variable (e.g. fit the logarithm of the response variable using a linear regression model, which implies – as noted above – that the response variable has a log-normal distribution rather than a normal distribution).
Independence of errors
誤差獨立性,即誤差與變項無相關,且服從常態分配。
This assumes that the errors of the response variables are uncorrelated with each other. (Actual statistical independence is a stronger condition than mere lack of correlation and is often not needed, although it can be exploited if it is known to hold.) Some methods (e.g. generalized least squares) are capable of handling correlated errors, although they typically require significantly more data unless some sort of regularization is used to bias the model towards assuming uncorrelated errors. Bayesian linear regression is a general way of handling this issue.
Lack of multicollinearity in the predictors
自變項具「非共線性」,即彼此獨立。幾何學上的意義,就是自變項必須是彼此兩兩正交(pairwise orthogonal)的。
For standard least squares estimation methods, the design matrix X must have full column rank p, i.e. be invertible; otherwise, we have a condition known as multicollinearity in the predictor variables. This can be triggered by having two or more perfectly correlated predictor variables (e.g. if the same predictor variable is mistakenly given twice, either without transforming one of the copies or by transforming one of the copies linearly). It can also happen if there is too little data available compared to the number of parameters to be estimated (e.g. fewer data points than regression coefficients). In the case of multicollinearity, the parameter vector β will be non-identifiable — it has no unique solution. At most we will be able to identify some of the parameters, i.e. narrow down its value to some linear subspace of Rp. See partial least squares regression. Methods for fitting linear models with multicollinearity have been developed; some require additional assumptions such as 「effect sparsity」 — that a large fraction of the effects are exactly zero. Note that the more computationally expensive iterated algorithms for parameter estimation, such as those used in generalized linear models, do not suffer from this problem — and in fact it's quite normal to when handling categorically-valued predictors to introduce a separate indicator variable predictor for each possible category, which inevitably introduces multicollinearity.
Sampling and design of experiments
研究方法的影響:抽樣方法、實驗設計…等等,均會產生影響。
Beyond these assumptions, several other statistical properties of the data
strongly influence the performance of different estimation methods:
The statistical relationship between the error terms and the regressors plays an
important role in determining whether an estimation procedure has desirable
sampling properties such as being unbiased and consistent.
The arrangement, or probability distribution of the predictor variables x has a
major influence on the precision of estimates of β. Sampling and design of
experiments are highly-developed subfields of statistics that provide guidance
for collecting data in such a way to achieve a precise estimate of β.
標準化迴歸係數的爭論
標準化迴歸係數在計量上的應用與解釋,文獻有許多爭論與修正意見。
統雄老師的建議:學習、反省、發展
就行為研究而言,更有許多超越計量技術、牽涉基礎知識論的問題。
大部分的行為研究,變項的測量與性質,與以上的前提與限制,牴觸是很嚴重的。如果沒有「反省」意識,很容易變成跑「垃圾進出(GIGO)」和作儀式。
但在學習階段,統雄老師建議暫時放下這些爭論,先學習前人對發展多元迴歸、解決問題的思想方法,培養從微積分、到統計的計量技術能力。
未來,可能不是修正,而是根本要放棄多元迴歸,探索、發展完全不同思想向面的解決方案。
 統雄數學樂學/統計神掌易經筋-問卷
統雄數學樂學/統計神掌易經筋-問卷


