

多元判定係數與標準化迴歸係數的應用與實作
Multiple Linear Regression, MLR
Practice
神掌打通任督二脈‧易筋經以簡馭繁
符號意義: 統雄快訣
統雄快訣
 延伸閱讀
延伸閱讀
 進階議題
進階議題
 警示訊息
警示訊息
選擇變數(Selection Variable)/實為選擇樣本
|
多元迴歸目的是以多個獨立自變項預測一個應變項,本文解說:迴歸係數與相關係數之不同,多元迴歸之變異數分析,假設檢定,多元判定係數,多元相關係數,未標準化迴歸係數,標準化迴歸係數,與自變項篩選方法。辨別b與β 的關係:變動vs.預測力。 下載SPSS範例實作,解說什麼是:迴歸方法的選擇、選擇變數(Selection Variable)、觀察值標記(Case Labels)、加權變項(WLS Weight)、選擇統計量、與報表詮釋。 |
多元迴歸分析特色
多元迴歸的目的是以多個自變項預測一個應變項,分析各自變項對應變項「獨立影響」的程度;同時具備篩選自變項的能力,從而發展、檢定多個包含不同自變項的模式。
多元迴歸分析是由Pearson(1908)所提出, 在傳統古典統計學教科書上,都把這項觀念作為統計的最高技術,實務上,也是建構各種多變項模型的基礎、扮演最重要的技術角色。
In statistics, linear regression is an approach to modeling the relationship between a scalar dependent variable y and one or more explanatory variables denoted X. The case of one explanatory variable is called simple regression. More than one explanatory variable is multiple regression. (This in turn should be distinguished from multivariate linear regression, where multiple correlated dependent variables are predicted, rather than a single scalar variable.)
In linear regression, data is modeled using linear predictor functions, and unknown model parameters are estimated from the data. Such models are called linear models. Most commonly, linear regression refers to a model in which the conditional mean of y given the value of X is an affine function of X. Less commonly, linear regression could refer to a model in which the median, or some other quantile of the conditional distribution of y given X is expressed as a linear function of X.
下載SPSS範例
下載SPSS高等統計範例資料(右鍵下載)Analy-SPSS-Teaching.exe
下載SPSS多變項分析範例資料(右鍵下載)Analy-SPSS-Teaching-Multi.rar
下載SPSS統計與多變項習題資料(右鍵下載)Analy-SPSS-Multi_Ex.7z
下載SPSS範例資料(教材專區)Analy-SPSS-Teaching.exe
下載範例資料(教材專區):Analy-SPSS-Teaching-Multi.exe
多元迴歸分析: SPSS 應用
應用範例
範例目的:5種網路使用行為對「平日網路使用時間」的多元迴歸分析。
前置研究:多元迴歸模型建構起點
資料分析程序通常是由單變項、雙變項,而多變項。
如果我們發現有2個以上自變項與某1應變項相關,就會繼續探索是否存在多變項模型的可能。
先作5種網路使用行為對「平日網路使用時間」的「簡單迴歸分析」,得報表如下。
其中:
F1;情色行為
F2;交友行為
F3;收集資訊行為
F4;遊戲行為
F5;禮儀行為
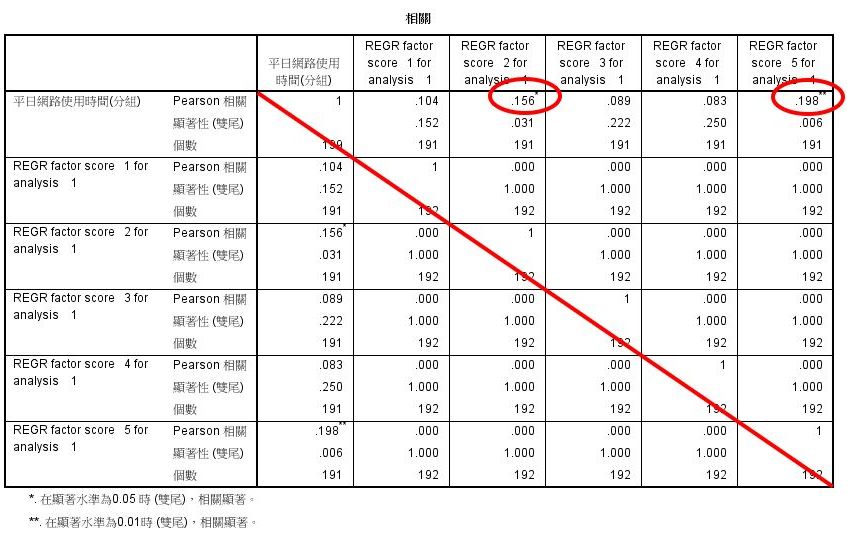
如果報表數據與以上不同,反映沒有做好「SPSS 資料清理」,請清理後重跑。
得知:F2、F5 與「平日網路使用時間」的相關分別達到 .05與.01 顯著水準。
由於 F1 ~ F5,都是由因素分析萃取出來的自變項(因素),彼此一定獨立,報表上也印證,彼此相關為0。
所以,F2、F5 與「平日網路使用時間」的相關係數:.156 與 .198,就是兩者「獨立影響」的程度了。
但為了教學目的,還是進一步作多元迴歸分析,以:
1. 展示多元迴歸分析的程序,與報表詮釋。
2. 印證多元迴歸分析,可以分析各自變項「獨立影響」的程度。
3. 印證多元迴歸分析,具備篩選自變項的能力。
理論敘述
使用者的5種網路行為:情色行為、交友行為、收集資訊行為、遊戲行為、禮儀行為。對上網使用時間均有獨立影響。
假設檢定
設:
β1;情色行為
β2;交友行為
β3;收集資訊行為
β4;遊戲行為
β5;禮儀行為
H0: βj=0 (j=1,2,…,5)
H1: βj≠0
這是一個習題,不是真正的研究。
〉迴歸方法
迴歸變項的選擇
>輸入應變項
gb4_n 平日網路使用時間(分組)"
>輸入自變項
5 種使用網路行為的因素
REGR factor score 1 ~ REGR factor score 5
漸增式批次迴歸分析設計
以上的自變項集,稱為「區塊 1/1」。
如果想作批次迴歸分析設計,則按:
〉下一個
〈自變數〉欄會清空
>輸入第二組自變項
如再 5 種使用網路行為的因素
REGR factor score 6 ~ REGR factor score 20
這個自變項集,則為「區塊 2/2」。
如此,可以跑 2 套(報表稱為「模式」)迴歸分析:
第一套:以REGR factor score 1 ~ REGR factor score 5 為自變項。
第二套為「漸增式」加入自變項:以REGR factor score 1 ~ REGR factor score 10 為自變項。
如此類推。
迴歸方法的選擇
>選擇變項進入方法
如果是初步的、探索的分析,我們想知道所有的自變項效果,我們就選「強迫進入」,新版中文為莫名其妙的「輸入」法。
而實務應用上,最後報告採用上,常用「逐步迴歸(stepwise)法。
其他選項
有特殊目的才設定,通常不選。
選擇變數(Selection Variable)
這是一個中文翻譯絕對容易產生誤導的名稱。實際的意義是根據某一變項,去「選擇樣本」,再按〈法則(Rules)〉,就是資料篩選 IF 指令的同樣功能。
觀察值標記(Case Labels)
這又是一個中文翻譯把人打趴的名稱。是指當選擇列印統計圖(Plots)時,在樣本點旁,列印樣本的指定屬性。
譬如,以使用時間為 Y 軸,以性別為 X 軸,但我們希望多知道該樣本的學校等級,就拉入「學校等級」這個變項,圖形就會顯示:大學、高中…等。
加權變項(WLS Weight)
根據某一變項對資料加權。
統雄老師已一再發現,加權法只是是資料「漂亮」,其實容易扭曲事實,違背知識,一定要少用、慎用、不用。
選擇統計量
選以上4個。
「共線性診斷」可以選,但本講義擬循序漸進,放在「中介模型分析」篇再介述。
報表詮釋
最前面的2個表:敘述統計、相關矩陣是基礎資料。
選入變數
表示先選入 F5,再選入 F1。
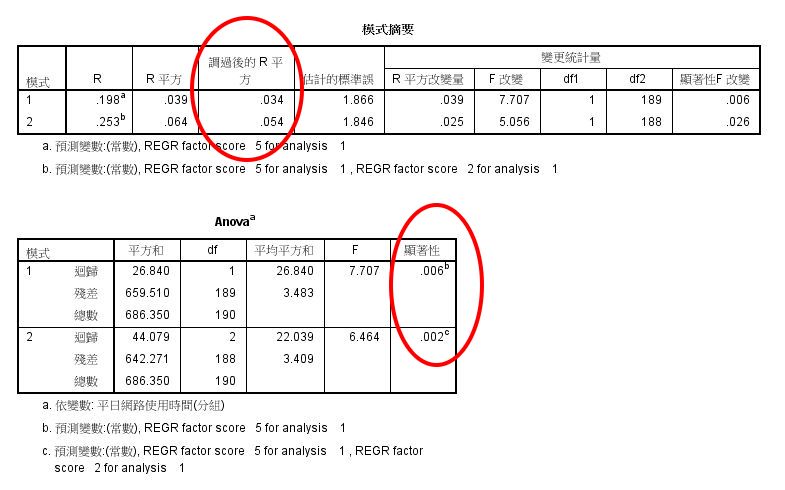
模式摘要‧ANOVA
模式摘要,最重要的是看「調過後的 R 平方」,即這2個自變項,分別可解釋/預測變異數的百分比。就其值而論,非常小。
ANOVA,變異數分析,印證簡單相關分析的結論:F2、F5 與「平日網路使用時間」的相關分別達到 .05與.01 顯著水準。
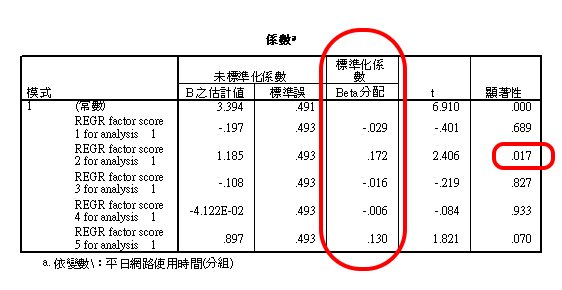
多元標準化迴歸係數
這是最重要的報表,達到顯著水準的 β 才有意義。
印證:如果只選入1個自變項時,其 β 與前置分析的相關係數相同,都是 .198。
但選入2個自變項時,也印證自變項愈多,R2 會變大,其 β 比前置分析的相關係數,會略高一點。
而其2個自變項的斜率,則分別為b:.379 與 .303。
多元迴歸模型預測力檢定
多元迴歸模型預測力檢定,程序如下:
建構多元迴歸模型
依據前節「多元標準化迴歸係數」表,得以建構:
Hat_gb4_n = .379F5 + .303F2 + 2.943
Hat_gb4_n,就是 gb4_n 變項的多元迴歸的估計模型公式。
確認預測力檢定資料
預測力檢定資料,一般可有2類。
訓練資料與檢定資料
如本例題,200筆資料是從大資料庫中抽出的「訓練資料」。
而「檢定資料」則是從相同大資料庫中抽出的另筆資料,如SPSS統計與多變項習題資料(右鍵下載)Analy-SPSS-Multi_Ex.7z。
真實資料
多元迴歸模型由歷史資料建構,而以未來發生的真實資料檢定。
多元迴歸模型預測資料‧檢定資料‧相關分析
以多元迴歸模型預測資料,與檢定資料,作兩者相關分析。
即在檢定資料集中,建構變項 Hat_gb4_n = .379F5 + .303F2 + 2.943
再以 Hat_gb4_n 與 gb4_n 作相關分析。
請將本多元迴歸模型預測力檢定,作為習題。
後繼研究:因子獨立性與模型修訂
注意:如果自變項彼此獨立(如本例,因為5個自變項都是經過萃取後的因素),多元迴歸的標準化β,和「自變項-應變項」兩兩的簡單相關r,值是一樣的。
但如果發現有明顯 β<r 的情形,那就表示因子之間有共變現象,因子之間不獨立,必須發展進一步的理論,,修訂為共變模型、中介模型…等。
 統雄數學樂學/統計神掌易經筋-問卷
統雄數學樂學/統計神掌易經筋-問卷




